In the summer of 2022, I interned at Shopee as a product analyst on the Search and Recommendation (SnR) data team. My primary responsibility was to deliver reliable and actionable analytics for product managers. Because we frequently ran large-scale queries throughout the day, any job delays or failures directly impacted reporting timelines and slowed progress toward feature improvements or releases.
Our main tools for data processing and querying were Presto and Apache Spark, supplemented by internal tools that abstracted away much of the underlying engineering complexity.
During my time there, there were some noticeable job failures and delays such that deadlines were unnecessarily pushed back. While I will analyze specific causes and fixes in a later section, an important backdrop was the company-wide resource shortage at the time. It was incredibly expensive to acquire compute resources, and the demand for compute due to increased workloads far outpaced the supply. This was especially challenging for the SnR team, where ML engineers were running intensive experiments on recommendation models that consumed substantial processing power.
Before we dive into the issue, I will first introduce the key technologies involved—namely Spark and YARN.
Apache Spark, originally developed as a research project in UC Berkeley and now maintained by the Apache Software Foundation, is an open-source distributed processing framework for large-scale data workloads. It leverages in-memory caching and optimized query execution to deliver high performance for analytic queries across massive datasets.
Spark was designed to overcome the limitations of MapReduce, which relies on a sequential, multi-step process susceptible to disk I/O latency. With Spark, data is read into memory, operations are performed, and results are written back—all in a streamlined process that avoids repeated disk access. The performance gains come primarily from Spark’s efficient use of in-memory data structures, such as Resilient Distributed Datasets (RDDs) and later DataFrames.
Today, Spark is widely used for machine learning, real-time analytics, interactive queries, and graph processing, making it a cornerstone of modern data engineering and analytics.
YARN, short for Yet Another Resource Negotiator, is Hadoop’s cluster resource management framework. Fun fact: “Yet Another” is an idiomatic qualifier programmers often use to acknowledge that many systems are incremental variations of existing ones—other examples include Yacc (Yet Another Compiler-Compiler) and YAML (Yet Another Markup Language).
Although I will not discuss YARN optimization in detail here, it is important to understand its role. Modern data architectures often run on clusters with thousands of nodes, where a single centralized controller cannot effectively manage the scale and complexity of resource allocation. YARN addresses this by separating resource management from job scheduling and monitoring.
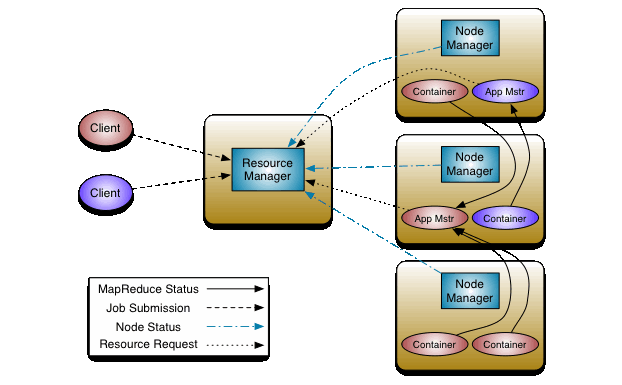
At its core, YARN consists of a global ResourceManager (RM) and per-node NodeManagers (NMs).
The ResourceManager contains two key components:
The ApplicationMaster negotiates resources from the Scheduler, manages task execution, and handles application-level fault tolerance and recovery in coordination with the NodeManagers.
Hadoop MapReduce running on YARN
Running Spark on YARN allows multiple frameworks (not just Spark) to dynamically share and centrally configure the same cluster resources. YARN’s schedulers handle categorization, isolation, and prioritization of workloads, ensuring resources are efficiently allocated instead of sitting idle. In short, YARN is one of the most widely used cluster managers for running large-scale Spark applications.