Log-Structured Merge-Tree (LSM-Tree) is an append-only, key-value data structure that provides high write throughput. Write throughput is the amount of data that can be written to a storage system over a period of time. LSM Tree is used by various databases including Apache Cassandra, LevelDB, and RocksDB just to name a few.
On a high level, LSM appends all incoming data then uses merge sort to handle deduplication and deletions. Underlying LSM are a few in-memory and on-disk data structures which will be explained in the following sections.
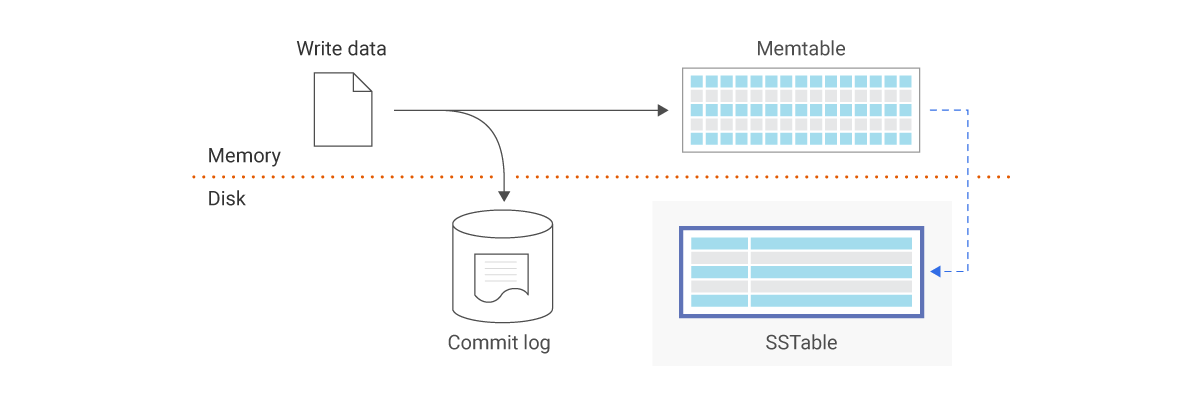
SSTable is a disk-based data structure consisting of a sorted, immutable sequence of key-value pairs. The sortedness allows for efficient data retrieval using algorithms like binary search.
Source: ScyllaDB
Initially, fresh write logs are buffered to an in-memory data structure called a Memtable. Once the Memtable reaches a configurable threshold, data is sorted and flushed to disk to become a new SSTable. In the diagram above, transactions are also appended to a Commit log or Write Ahead Log (WAL) file to recover from a crash and ensure durability. As more SSTables are added and a certain threshold is reached, the SSTables are merged via compaction to form a larger SSTable. Note that updates to a given key will just append the new key value. Older entries will eventually be removed during compaction.
Compaction can be thought of as garbage collection for the LSM tree. It removes keys that are duplicated and/or marked for deletion. Under the hood, it utilizes a multiway merge algorithm to merge multiple SSTables into a new SSTable.
In most implementations, a dedicated background thread is used to perform compaction. There are many ways to customize how and when compaction gets triggered with different tradeoffs. Below are two classic compaction strategies.

Source: RocksDB

Source: Alibaba Cloud